 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
TabClustPFN: A Prior-Fitted Network for Tabular Data Clustering
Jan 29, 2026Clustering tabular data is a fundamental yet challenging problem due to heterogeneous feature types, diverse data-generating mechanisms, and the absence of transferable inductive biases across datasets. Prior-fitted networks (PFNs) have recently demonstrated strong generalization in supervised tabular learning by amortizing Bayesian inference under a broad synthetic prior. Extending this paradigm to clustering is nontrivial: clustering is unsupervised, admits a combinatorial and permutation-invariant output space, and requires inferring the number of clusters. We introduce TabClustPFN, a prior-fitted network for tabular data clustering that performs amortized Bayesian inference over both cluster assignments and cluster cardinality. Pretrained on synthetic datasets drawn from a flexible clustering prior, TabClustPFN clusters unseen datasets in a single forward pass, without dataset-specific retraining or hyperparameter tuning. The model naturally handles heterogeneous numerical and categorical features and adapts to a wide range of clustering structures. Experiments on synthetic data and curated real-world tabular benchmarks show that TabClustPFN outperforms classical, deep, and amortized clustering baselines, while exhibiting strong robustness in out-of-the-box exploratory settings. Code is available at https://github.com/Tianqi-Zhao/TabClustPFN.
Data-Driven Generation of Neutron Star Equations of State Using Variational Autoencoders
Jan 29, 2026We develop a machine learning model based on a structured variational autoencoder (VAE) framework to reconstruct and generate neutron star (NS) equations of state (EOS). The VAE consists of an encoder network that maps high-dimensional EOS data into a lower-dimensional latent space and a decoder network that reconstructs the full EOS from the latent representation. The latent space includes supervised NS observables derived from the training EOS data, as well as latent random variables corresponding to additional unspecified EOS features learned automatically. Sampling the latent space enables the generation of new, causal, and stable EOS models that satisfy astronomical constraints on the supervised NS observables, while allowing Bayesian inference of the EOS incorporating additional multimessenger data, including gravitational waves from LIGO/Virgo and mass and radius measurements of pulsars. Based on a VAE trained on a Skyrme EOS dataset, we find that a latent space with two supervised NS observables, the maximum mass $(M_{\max})$ and the canonical radius $(R_{1.4})$, together with one latent random variable controlling the EOS near the crust--core transition, can already reconstruct Skyrme EOSs with high fidelity, achieving mean absolute percentage errors of approximately $(0.15\%)$ for $(M_{\max})$ and $(R_{1.4})$ derived from the decoder-reconstructed EOS.
GNN-MultiFix: Addressing the pitfalls for GNNs for multi-label node classification
Nov 21, 2024



Graph neural networks (GNNs) have emerged as powerful models for learning representations of graph data showing state of the art results in various tasks. Nevertheless, the superiority of these methods is usually supported by either evaluating their performance on small subset of benchmark datasets or by reasoning about their expressive power in terms of certain graph isomorphism tests. In this paper we critically analyse both these aspects through a transductive setting for the task of node classification. First, we delve deeper into the case of multi-label node classification which offers a more realistic scenario and has been ignored in most of the related works. Through analysing the training dynamics for GNN methods we highlight the failure of GNNs to learn over multi-label graph datasets even for the case of abundant training data. Second, we show that specifically for transductive node classification, even the most expressive GNN may fail to learn in absence of node attributes and without using explicit label information as input. To overcome this deficit, we propose a straightforward approach, referred to as GNN-MultiFix, that integrates the feature, label, and positional information of a node. GNN-MultiFix demonstrates significant improvement across all the multi-label datasets. We release our code at https://anonymous.4open.science/r/Graph-MultiFix-4121.
A data-centric approach for assessing progress of Graph Neural Networks
Jun 18, 2024


Graph Neural Networks (GNNs) have achieved state-of-the-art results in node classification tasks. However, most improvements are in multi-class classification, with less focus on the cases where each node could have multiple labels. The first challenge in studying multi-label node classification is the scarcity of publicly available datasets. To address this, we collected and released three real-world biological datasets and developed a multi-label graph generator with tunable properties. We also argue that traditional notions of homophily and heterophily do not apply well to multi-label scenarios. Therefore, we define homophily and Cross-Class Neighborhood Similarity for multi-label classification and investigate $9$ collected multi-label datasets. Lastly, we conducted a large-scale comparative study with $8$ methods across nine datasets to evaluate current progress in multi-label node classification. We release our code at \url{https://github.com/Tianqi-py/MLGNC}.
Multi-label Node Classification On Graph-Structured Data
Apr 20, 2023Graph Neural Networks (GNNs) have shown state-of-the-art improvements in node classification tasks on graphs. While these improvements have been largely demonstrated in a multi-class classification scenario, a more general and realistic scenario in which each node could have multiple labels has so far received little attention. The first challenge in conducting focused studies on multi-label node classification is the limited number of publicly available multi-label graph datasets. Therefore, as our first contribution, we collect and release three real-world biological datasets and develop a multi-label graph generator to generate datasets with tunable properties. While high label similarity (high homophily) is usually attributed to the success of GNNs, we argue that a multi-label scenario does not follow the usual semantics of homophily and heterophily so far defined for a multi-class scenario. As our second contribution, besides defining homophily for the multi-label scenario, we develop a new approach that dynamically fuses the feature and label correlation information to learn label-informed representations. Finally, we perform a large-scale comparative study with $10$ methods and $9$ datasets which also showcase the effectiveness of our approach. We release our benchmark at \url{https://anonymous.4open.science/r/LFLF-5D8C/}.
ECG Heartbeat classification using deep transfer learning with Convolutional Neural Network and STFT technique
Jul 05, 2022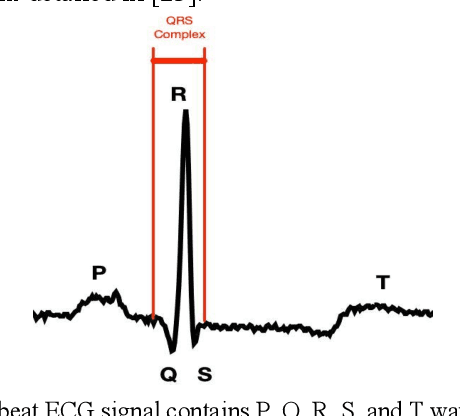
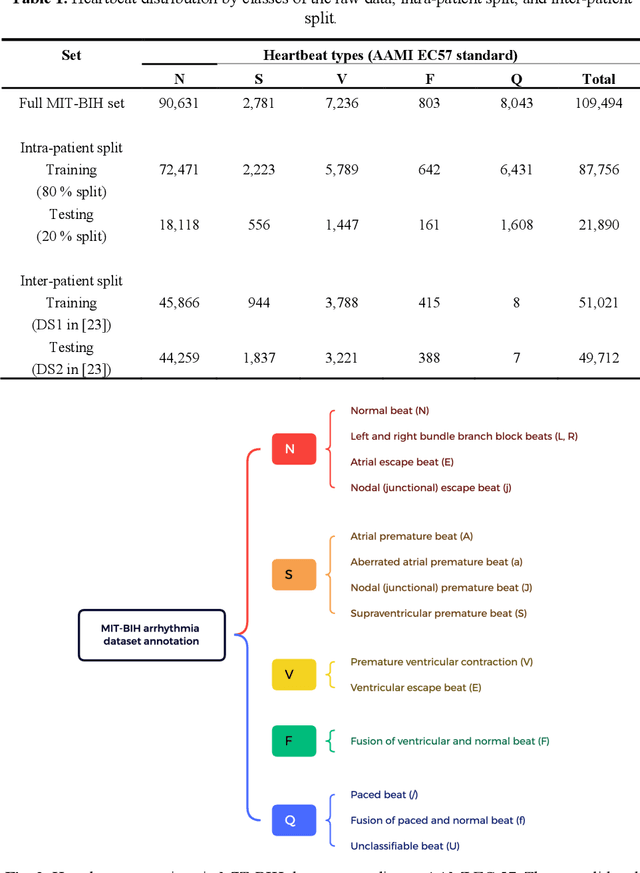
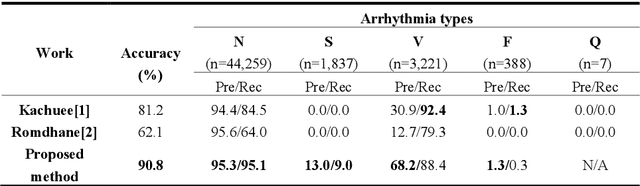
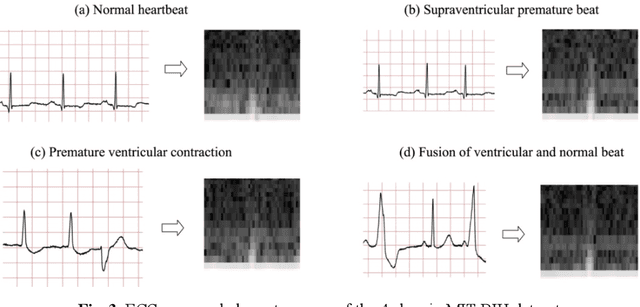
Electrocardiogram (ECG) is a simple non-invasive measure to identify heart-related issues such as irregular heartbeats known as arrhythmias. While artificial intelligence and machine learning is being utilized in a wide range of healthcare related applications and datasets, many arrhythmia classifiers using deep learning methods have been proposed in recent years. However, sizes of the available datasets from which to build and assess machine learning models is often very small and the lack of well-annotated public ECG datasets is evident. In this paper, we propose a deep transfer learning framework that is aimed to perform classification on a small size training dataset. The proposed method is to fine-tune a general-purpose image classifier ResNet-18 with MIT-BIH arrhythmia dataset in accordance with the AAMI EC57 standard. This paper further investigates many existing deep learning models that have failed to avoid data leakage against AAMI recommendations. We compare how different data split methods impact the model performance. This comparison study implies that future work in arrhythmia classification should follow the AAMI EC57 standard when using any including MIT-BIH arrhythmia dataset.
Deep Multimodal Learning: An Effective Method for Video Classification
Nov 30, 2018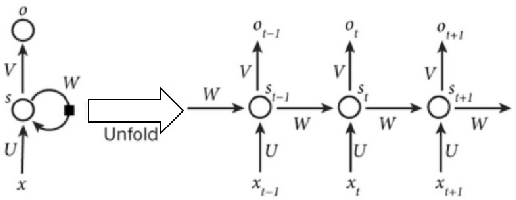
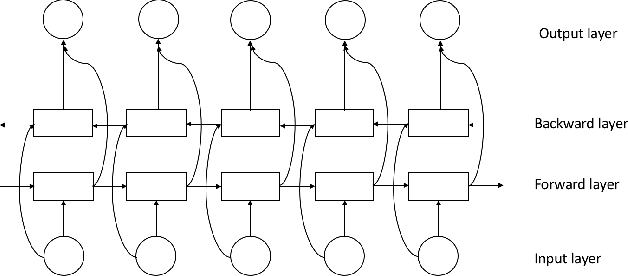
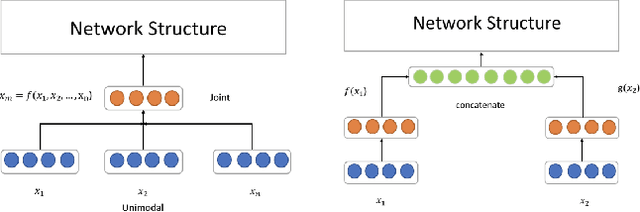
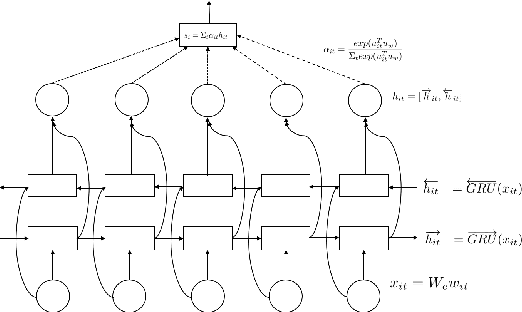
Videos have become ubiquitous on the Internet. And video analysis can provide lots of information for detecting and recognizing objects as well as help people understand human actions and interactions with the real world. However, facing data as huge as TB level, effective methods should be applied. Recurrent neural network (RNN) architecture has wildly been used on many sequential learning problems such as Language Model, Time-Series Analysis, etc. In this paper, we propose some variations of RNN such as stacked bidirectional LSTM/GRU network with attention mechanism to categorize large-scale video data. We also explore different multimodal fusion methods. Our model combines both visual and audio information on both video and frame level and received great result. Ensemble methods are also applied. Because of its multimodal characteristics, we decide to call this method Deep Multimodal Learning(DML). Our DML-based model was trained on Google Cloud and our own server and was tested in a well-known video classification competition on Kaggle held by Google.
Monocular Depth Estimation with Augmented Ordinal Depth Relationships
Jun 02, 2018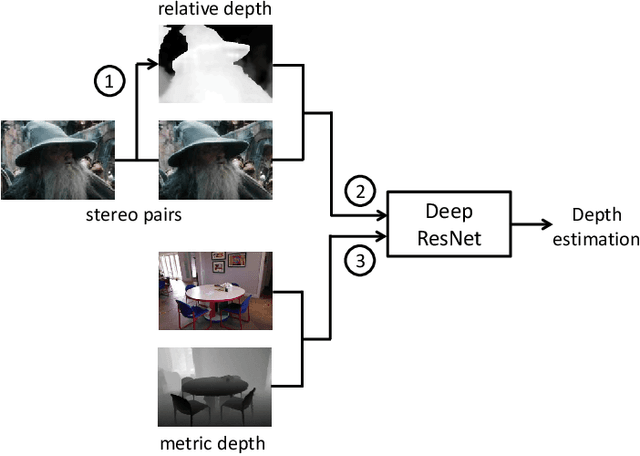

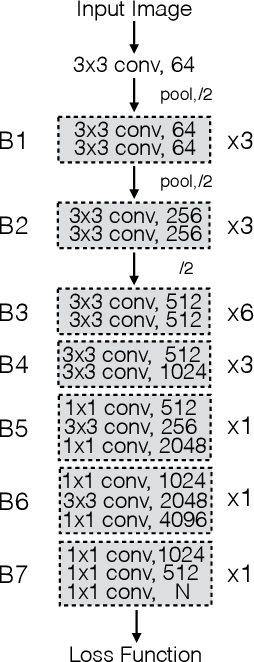
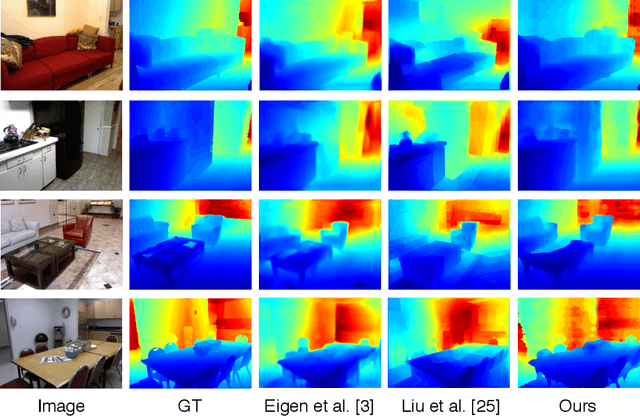
Most existing algorithms for depth estimation from single monocular images need large quantities of metric groundtruth depths for supervised learning. We show that relative depth can be an informative cue for metric depth estimation and can be easily obtained from vast stereo videos. Acquiring metric depths from stereo videos is sometimes impracticable due to the absence of camera parameters. In this paper, we propose to improve the performance of metric depth estimation with relative depths collected from stereo movie videos using existing stereo matching algorithm. We introduce a new "Relative Depth in Stereo" (RDIS) dataset densely labelled with relative depths. We first pretrain a ResNet model on our RDIS dataset. Then we finetune the model on RGB-D datasets with metric ground-truth depths. During our finetuning, we formulate depth estimation as a classification task. This re-formulation scheme enables us to obtain the confidence of a depth prediction in the form of probability distribution. With this confidence, we propose an information gain loss to make use of the predictions that are close to ground-truth. We evaluate our approach on both indoor and outdoor benchmark RGB-D datasets and achieve state-of-the-art performance.
Episodic Memory Deep Q-Networks
May 19, 2018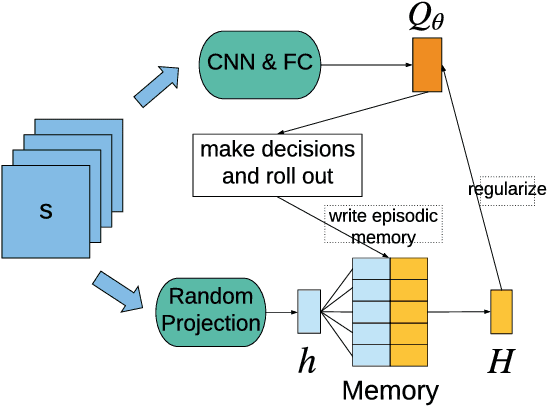
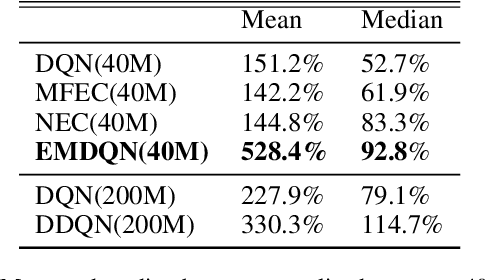
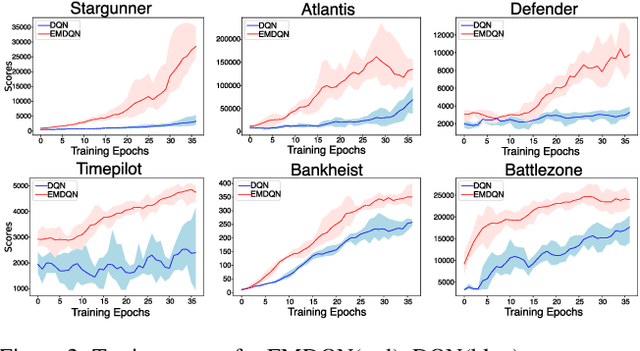
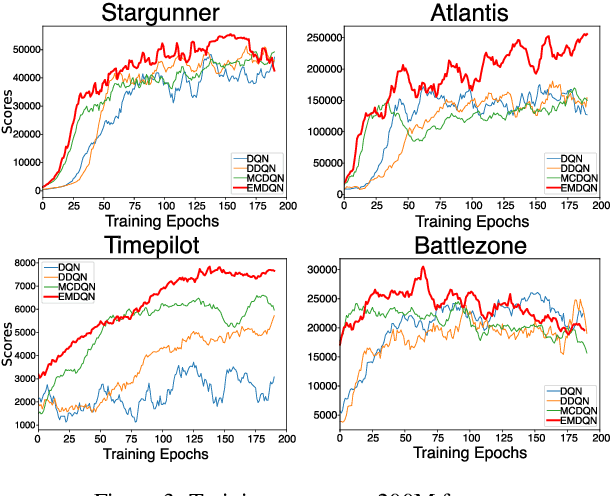
Reinforcement learning (RL) algorithms have made huge progress in recent years by leveraging the power of deep neural networks (DNN). Despite the success, deep RL algorithms are known to be sample inefficient, often requiring many rounds of interaction with the environments to obtain satisfactory performance. Recently, episodic memory based RL has attracted attention due to its ability to latch on good actions quickly. In this paper, we present a simple yet effective biologically inspired RL algorithm called Episodic Memory Deep Q-Networks (EMDQN), which leverages episodic memory to supervise an agent during training. Experiments show that our proposed method can lead to better sample efficiency and is more likely to find good policies. It only requires 1/5 of the interactions of DQN to achieve many state-of-the-art performances on Atari games, significantly outperforming regular DQN and other episodic memory based RL algorithms.